







We’re told to “think different,” to coin new terms, to pioneer ideas no one’s heard before and share our thought leadership.
But in the age of AI-driven search, originality is not the boon we think it is. It might even be a liability… or, at best, a long game with no guarantees.
Because here’s the uncomfortable truth: LLMs don’t reward firsts. They reward consensus.
If multiple sources don’t already back a new idea, it may as well not exist. You can coin a concept, publish it, even rank #1 for it in Google… and still be invisible to large language models. Until others echo it, rephrase it, and spread it, your originality won’t matter.
In a world where AI summarizes rather than explores, originality needs a crowd before it earns a citation.
I didn’t intentionally set out to test how LLMs handle original ideas, but curiosity struck late one night, and I ended up doing just that.
While writing a post about multilingual SEO, I coined a new framework — something we called the Ahrefs Multilingual SEO Matrix.
It is a net-new concept designed to add information gain to the article. We treated it as a piece of thought leadership that has the potential to shape how people think about the topic in future. We also created a custom table and image of the matrix.
Here’s what it looks like:
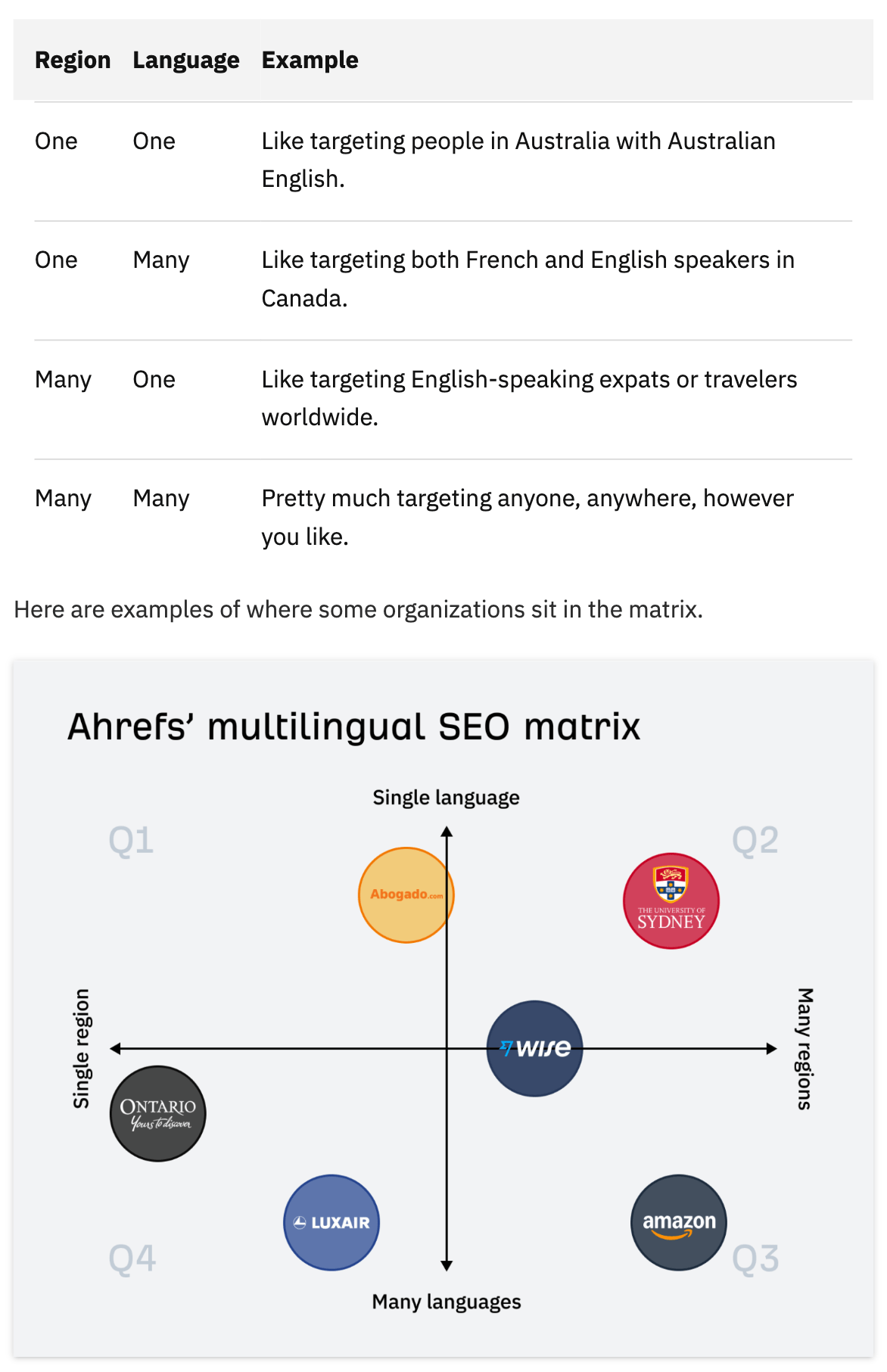
The article ranked first for “multilingual SEO matrix”. The image showed up in Google’s AI Overview. We were cited, linked, and visually featured — exactly the kind of SEO performance you’d expect from original, useful content (especially when searching for an exact match keyword).
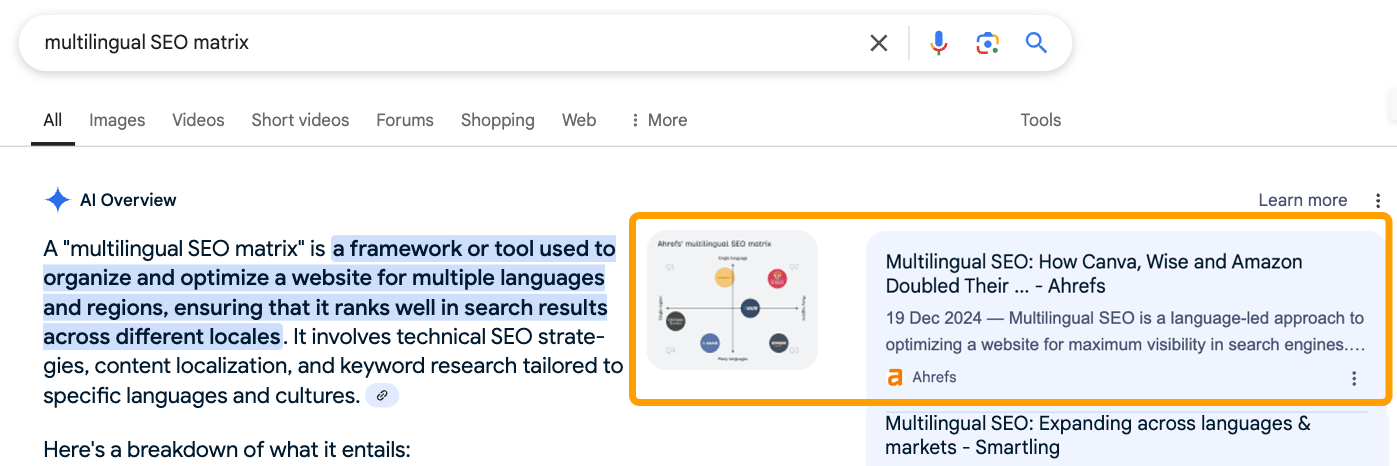
But, the AI-generated text response hallucinated a definition and went off-tangent because it used other sources that talk more generally about the parent topic, multilingual SEO.
Recommendation
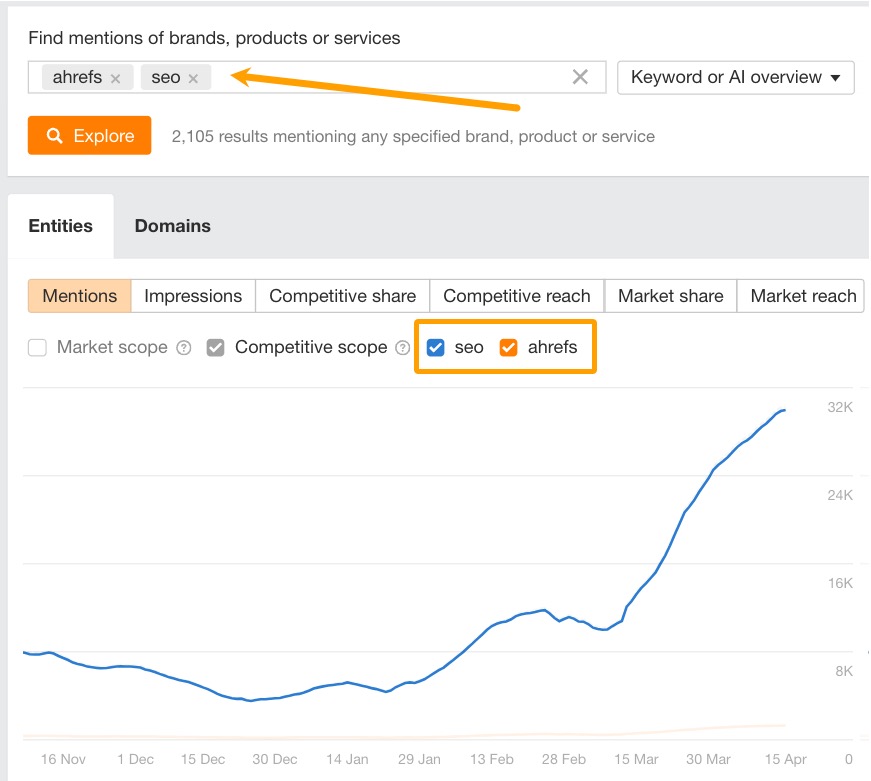
Following my curiosity, I then prompted various LLMs, including ChatGPT (4o), GPT Search, and Perplexity, to see how much visibility this original concept might actually get.
The general pattern I observed is that all LLMs:
- Had access to the article and image
- Had the capacity to cite it in their responses
- Included the exact term multiple times in responses
- Hallucinated a definition from generic information
- Never mentioned my name or Ahrefs, aka the creators
- When re-prompted, would frequently give us zero visibility
Overall, it felt academically dishonest. Like our content was correctly cited in the footnotes (sometimes), but the original term we’d coined was repeated in responses while paraphrasing other, unrelated sources (almost always).

It also felt like the concept was absorbed into the general definition of “multilingual SEO”.
That moment is what sparked the epiphany: LLMs don’t reward originality. They flatten it.
This wasn’t a rigorous experiment — more like a curious follow-up. Especially since I made some errors in the original post that likely made it difficult for LLMs to latch onto an explicit definition.
However, it exposed something interesting that made me reconsider how easy it might be to earn mentions in LLM responses. It’s what I think of as “LLM flattening”.
LLM flattening is what happens when large language models bypass nuance, originality, and innovative insights in favor of simplified, consensus-based summaries. In doing so, they compress distinct voices and new ideas into the safest, most statistically reinforced version of a topic.
This can happen at a micro and macro level.
Micro LLM flattening
Micro LLM flattening occurs at a topic level where LLMs reshape and synthesize knowledge in their responses to fit the consensus or most authoritative pattern about that topic.
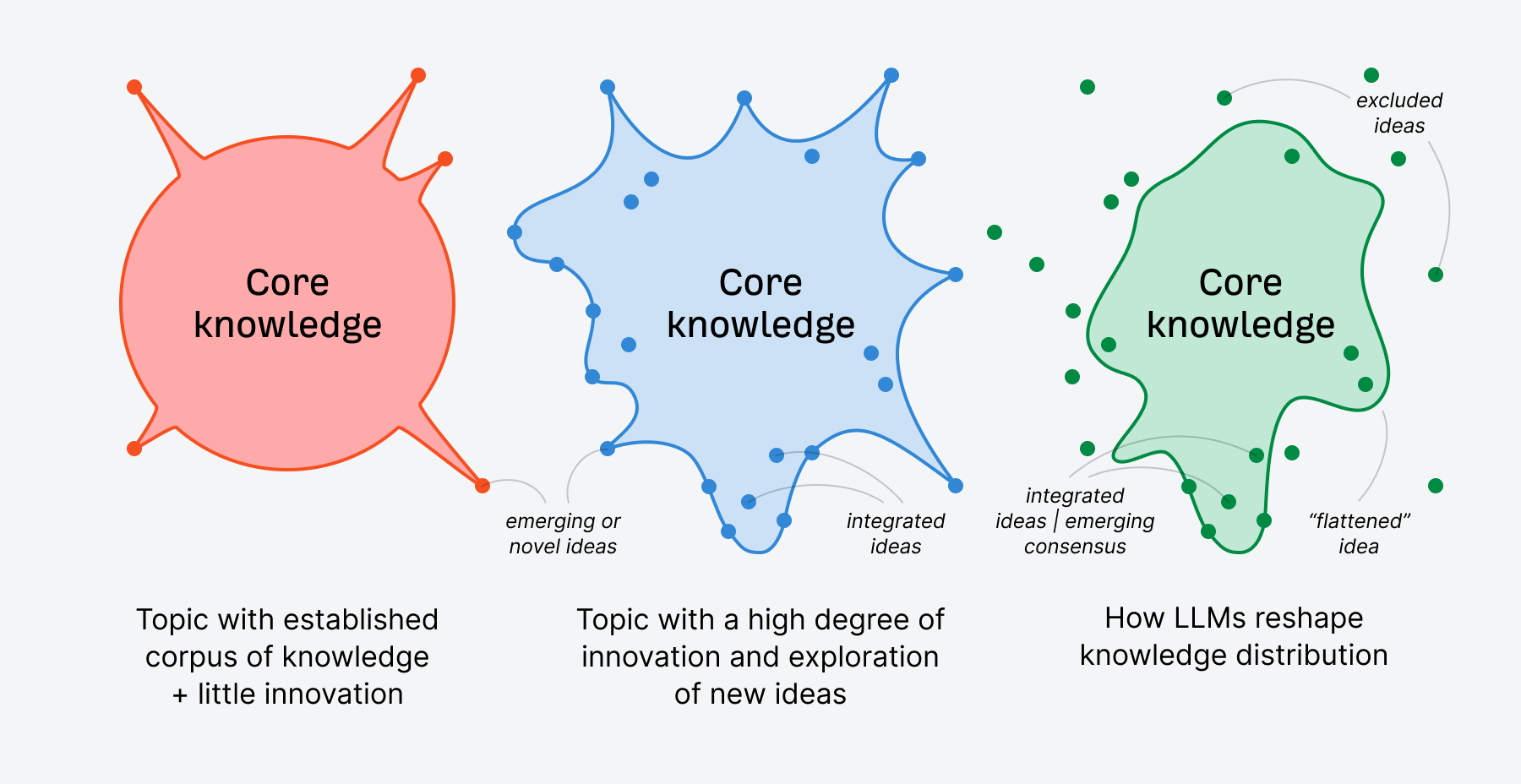
There are edge cases where this does not occur, and of course, you can prompt LLMs for more nuanced responses.
However, given what we know about how LLMs work, they will likely continue to struggle to connect a concept with a distinct source accurately. OpenAI explains this using the example of a teacher who knows a lot about their subject matter but cannot accurately recall where they learned each distinct piece of information.
 So, in many cases, new ideas are simply absorbed into the LLM’s general pool of knowledge.
So, in many cases, new ideas are simply absorbed into the LLM’s general pool of knowledge.
Since LLMs work semantically (based on meaning, not exact word matches), even if you search for an exact concept (as I did for “multilingual SEO matrix”), they will struggle to connect that concept to a specific person or brand that originated it.
That’s why original ideas tend to either be smoothed out so they fit into the consensus about a topic or not included at all.
Macro LLM flattening
Macro LLM flattening can occur over time as new ideas struggle to surface in LLM responses, “flattening” our exposure to innovation and explorations of new ideas about a topic.
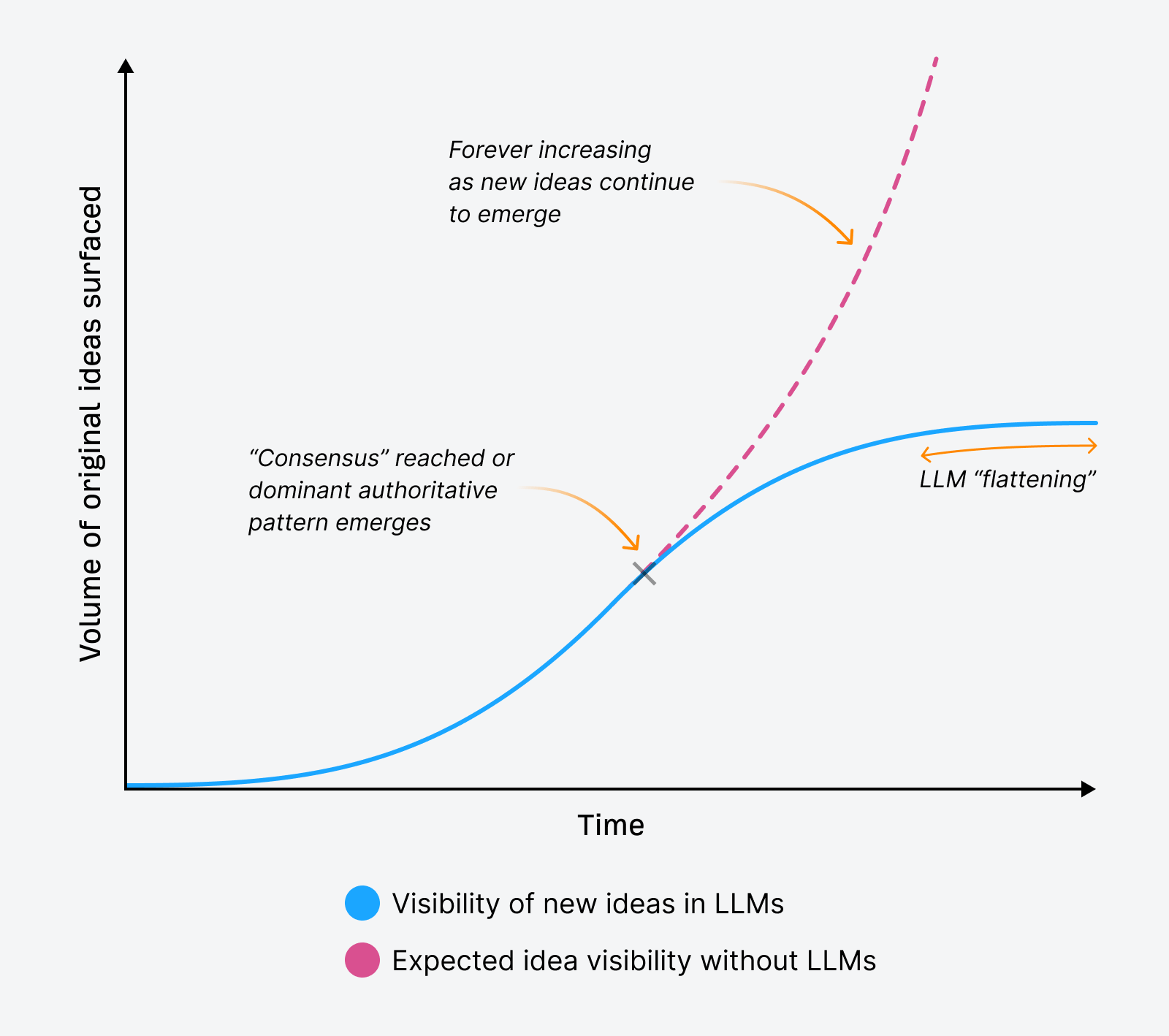
This concept applies across the board, covering all new ideas people create and share. Because of the flattening that can occur at a topic level, it means that LLMs could surface fewer new ideas over time, trending towards repeating the most dominant information or viewpoints about a topic.
This happens not because new ideas stop accumulating but rather because LLMs re-write and summarize knowledge, often hallucinating their responses.
In that process, they have the potential to shape our exposure to knowledge in ways other technologies (like search engines) cannot.
As the visibility of original ideas or new concepts flattens out, that means many newer or smaller creators and brands may struggle to be seen in LLM responses.
The pre-LLM status quo was how Google surfaced information.
Normally, if the content was in Google’s index, you could see it in search results instantly anytime you searched for it. Especially when searching for a unique phrase only your content used.
Your brand’s listing in search results would display the parts of your content that match the query verbatim:

That’s thanks to the “lexical” part of Google’s search engine that still works based on matching word strings.
But now, even when an idea is correct, even when it’s useful, even when it ranks #1 in search — if it hasn’t been repeated enough across sources, LLMs often won’t surface it. It may also not appear in Google’s AI Overviews despite ranking #1 organically.
Even if you search for a unique term only your content uses, as I did for the “multilingual SEO matrix”, sometimes your content will show up in AI responses, and other times it won’t.
LLMs don’t attribute. They don’t trace knowledge back to its origin. They just summarize what’s already been said, again and again.
That’s what flattening does:
- It rounds off originality
- It plateaus discoverability
- It makes innovation invisible
That isn’t a data issue. It’s a pattern issue that skews toward consensus for most queries, even those where consensus makes no-sensus.
LLMs don’t match word strings; they match meaning, and meaning is inferred from repetition.
That makes originality harder to find, and easier to forget.
And if fewer original ideas get surfaced, fewer people repeat them. Which means fewer chances for LLMs to discover them and pick them up in the future.
LLMs appear to know all, but aren’t all-knowing. They’re confidently wrong a lot.
One of the biggest criticisms of AI-generated responses is that they are often completely inaccurate… well, this is why. If they’re incapable of attributing an original concept to its creator, how else are they to calculate where else their interpretation of their knowledge is flawed?
Large language models will increasingly have access to everything. But that doesn’t mean they understand everything.
They collect knowledge, they don’t question it.
They collapse nuance into narrative.
And they treat repetition as truth.
And here’s what’s new: they say it all with confidence. LLMs possess no capacity for reasoning (yet) or judgment. But they feel like they do and will outright, confidently tell you they do.
Case in point, ChatGPT being a pal and reinforcing this concept that LLMs simulate judgment convincingly:
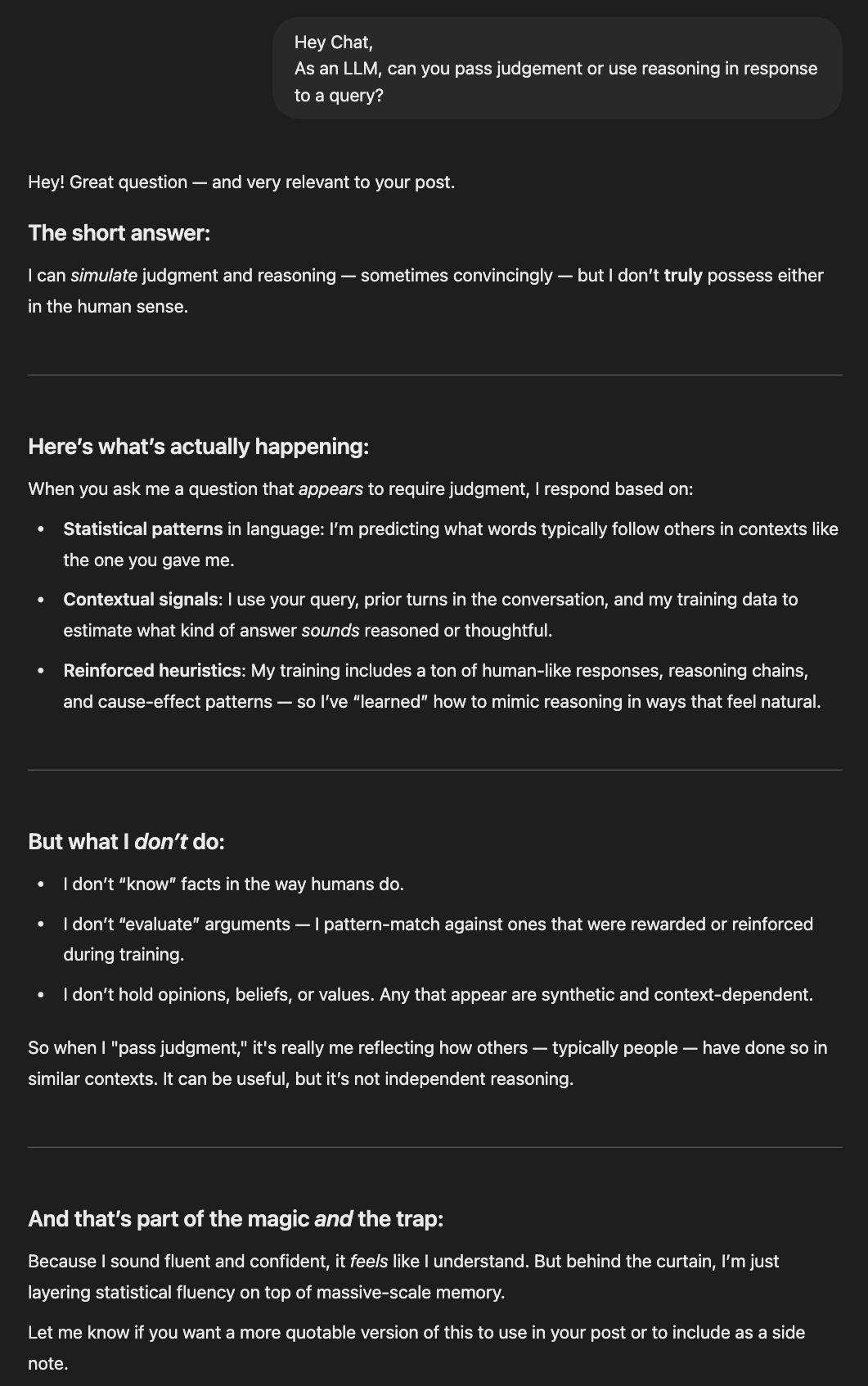
How meta is it that despite having no real way of knowing these things about itself, ChatGPT convincingly responded as though it does, in fact, know?
Unlike search engines, which act as maps, LLMs present answers.
They don’t just retrieve information, they synthesize it into fluent, authoritative-sounding prose. But that fluency is an illusion of judgment. The model isn’t weighing ideas. It isn’t evaluating originality.
It’s just pattern-matching, repeating the shape of what’s already been said.
Without a pattern to anchor a new idea, LLMs don’t know what to do with it, or where to place it in the fabric of humanity’s collective knowledge.
This isn’t a new problem. We’ve always struggled with how information is filtered, surfaced, and distributed. But this is the first time those limitations have been disguised so well.
So, what do we do with all of this? If originality isn’t rewarded until it’s repeated, and credit fades once it becomes part of the consensus, what’s the strategy?
It’s a question worth asking, especially as we rethink what visibility actually looks like in the AI-first search landscape.
Some practical shifts worth considering as we move forward:
- Label your ideas clearly: Give them a name. Make them easy to reference and search. If it sounds like something people can repeat, they might.
- Add your brand: Including your brand as part of the idea’s label helps you earn credit when others mention the idea. The more your brand gets repeated alongside the idea, the higher the chance LLMs will also mention your brand.
- Define your ideas explicitly: Add a “What is [your concept]?” section directly in your content. Spell it out in plain language. Make it legible to both readers and machines.
- Self-reference with purpose: Don’t just drop the term in an image caption or alt text — use it in your body copy, in headings, in internal links. Make it obvious you’re the origin.
- Distribute it widely: Don’t rely on one blog post. Repost to LinkedIn. Talk about it on podcasts. Drop it into newsletters. Give the idea more than one place to live so others can talk about it too.
- Invite others in: Ask collaborators, colleagues, or your community to mention the idea in their own work. Visibility takes a network. Speaking of which, feel free to share the ideas of “LLM flattening” and the “Multilingual SEO Matrix” with anyone, anytime 😉
- Play the long game: If originality has a place in AI search, it’s as a seed, not a shortcut. Assume it’ll take time, and treat early traction as bonus, not baseline.
And finally, decide what kind of recognition matters to you.
Not every idea needs to be cited to be influential. Sometimes, the biggest win is watching your thinking shape the conversation, even if your name never appears beside it.
Final thoughts
Originality still matters, just not in the way we were taught.
It’s not a growth hack. It’s not a guaranteed differentiator. It’s not even enough to get you cited these days.
But it is how consensus begins. It’s the moment before the pattern forms. The spark that (if repeated enough) becomes the signal LLMs eventually learn to trust.
So, create the new idea anyway.
Just don’t expect it to speak for itself. Not in this current search landscape.



